
关于与“
耦合 (概率)”标题相近或相同的条目页,请见“
耦合”。
耦合,或称关联结构(英语:Copula),为处理统计中随机变量相关性问题的一种方法,由一组随机变量的边际分布来确定它们的联合分布。通过关联结构来确定一个联合分布的方法是基于如下思想,一个简单转换可以通过分别将每个边缘分布都转换为平均分布的转换组成。这样,一个关联结构(dependence structure)就可以表达为一个基于上述所得平均分布之上的联合分布,而关联结构(copula)即是边缘均匀随机变量之上的一个联合分布。在实际应用中,上述的转换可能被设置为每个边缘变量的初始化步骤,或者上述转换的参数可能根据具体关联结构的对应参数设置。
按照所表达的关联关系的不同,关联结构被分为很多不同类别。典型情况下,一个种类的关联结构有多个参数用来表达不同的关联强度和关联类型。下面将大概描述一些有代表性的关联结构。关联结构的一个典型应用是,通过选择某一种类的关联结构来定义某一适合特定样本数据分布的联合分布,当然关联结构也可以来自于任何相应的给定联合分布。
基本思想[编辑]
考察两个随机变量 ,
,  ,分别具有连续累积分布函数
,分别具有连续累积分布函数 和
和 。通过分别在两个随机变量上应用概率积分转换,得到
。通过分别在两个随机变量上应用概率积分转换,得到 和
和 。因此
。因此 和
和 都是具有连续均匀分布的变量,相关性通常取决于和是否是相关(自然,如果和是不相关的,那么和也是不相关的)。因为这个转换是可逆的,可以定义和之间的相关性等于和之间的相关性。因为和是均匀分布的随机变量,所以问题被简化为定义一个在两个均匀分布之上的二项分布,这就是关联结构。所以,这一基本思想就是,通过把边缘变量转化为均匀分布变量而不再需要考察很多不同的边缘分布以简化问题,然后再把相关性定义为一个在均匀分布之上的联合分布。
都是具有连续均匀分布的变量,相关性通常取决于和是否是相关(自然,如果和是不相关的,那么和也是不相关的)。因为这个转换是可逆的,可以定义和之间的相关性等于和之间的相关性。因为和是均匀分布的随机变量,所以问题被简化为定义一个在两个均匀分布之上的二项分布,这就是关联结构。所以,这一基本思想就是,通过把边缘变量转化为均匀分布变量而不再需要考察很多不同的边缘分布以简化问题,然后再把相关性定义为一个在均匀分布之上的联合分布。
一个 关联结构是一个定义在 维单位立方体
维单位立方体![{\displaystyle [0,1]^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/40160923273b7109968df994dca832b91d957bf2) 上的多元联合分布,其每个边缘分布都是在
上的多元联合分布,其每个边缘分布都是在![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d) 区间上的均匀分布。
区间上的均匀分布。
特别的,![{\displaystyle C:[0,1]^{n}\to [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/53b2b681ee3ea29b8167f74e3f2a7ce63c9fe526) 是一个n维关联结构,有
是一个n维关联结构,有
 当
当![{\displaystyle \mathbf {u} \in [0,1]^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bcc42725263258e32824fd088caf3845ce136a65) 有至少一个分量为
有至少一个分量为
 当所有分量为
当所有分量为 除了第i个分量等于
除了第i个分量等于
 是n维递增的,也即,有每个hyperrectangle
是n维递增的,也即,有每个hyperrectangle ![{\displaystyle B=\times _{i=1}^{n}[x_{i},y_{i}]\subseteq [0,1]^{n};}](https://wikimedia.org/api/rest_v1/media/math/render/svg/875e7cd28ac43fb49f828ebd98216e62654454ed)

其中 。
。 所谓的
所谓的 的C-体积(volume)。
的C-体积(volume)。
Sklar定理[编辑]
由Sklar提出的这条定理[1]是大多数关联结构的应用的基础。Sklar定理指出,一个给定的 个变量的联合分布函数
个变量的联合分布函数 ,
, 为其边缘分布函数,必存在这样一个关联结构
为其边缘分布函数,必存在这样一个关联结构 使
使
以二项分布为例,Sklar定理应用如下。对任一二项分布函数 ,令
,令 而
而 为其单变量边缘概率分布函数。那么存在关联结构以使
为其单变量边缘概率分布函数。那么存在关联结构以使

(此处已知分布和它的累积分布函数)。此外,如果边缘分布 和
和 连续,那么关联结构函数是唯一的。否则,关联结构在边缘分布的值域上是唯一确定的。
连续,那么关联结构函数是唯一的。否则,关联结构在边缘分布的值域上是唯一确定的。
弗雷歇–霍夫丁(Fréchet–Hoeffding)关联结构边界[编辑]
 Graphs of the Fréchet–Hoeffding copula limits and of the independence copula (in the middle).
Graphs of the Fréchet–Hoeffding copula limits and of the independence copula (in the middle).
最小(反单调)关联结构:是所有关联结构的下边界。仅在二项分布中,变量间表现为完全负相关。

对n-元关联结构,下边界为

最大 (共单调 ) 关联结构:是所有关联结构的上边界。其在二项分布中,变量间表现为完全正相关:

对n-元关联结构,上边界为

结论:对所有关联结构C(u, v),

对于多元关联的情况为

关联结构种类[编辑]
正态关联结构[编辑]
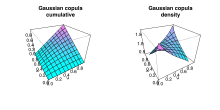 Cumulative distribution and probability density functions of Gaussian copula with
Cumulative distribution and probability density functions of Gaussian copula with 
在金融建模中常用到的一个关联结构是正态关联结构,正态关联结构是根据Sklar定理由二元正态分布构成。设 是标准二元正态累积分布函数,相关系数为ρ,则正态关联结构函数为
是标准二元正态累积分布函数,相关系数为ρ,则正态关联结构函数为

其中,![{\displaystyle u,v\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/83a46d1b72265ce8f3f85a0368d1849bcb59bbff) 而
而 表示标准正态累积分布函数。
表示标准正态累积分布函数。
对C微分得出关联结构的密度函数:

其中
![{\displaystyle \varphi _{X,Y,\rho }(x,y)={\frac {1}{2\pi {\sqrt {1-\rho ^{2}}}}}\exp \left(-{\frac {1}{2(1-\rho ^{2})}}\left[{x^{2}+y^{2}}-2\rho xy\right]\right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6fab21cdd90debffb401219f3f017ad95c636b39)
是皮尔逊矩相关系数为 标准二元正态分布的概率密度函数,其标准正态密度为
标准二元正态分布的概率密度函数,其标准正态密度为 。
。
参考资料[编辑]
- ^ Sklar, A. Fonctions de répartition à n dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris. 1959, 8: 229–231.


