格羅弗演算法(英語:Grover's algorithm)是一種量子演算法,於1996年由電腦科學家洛夫·格羅弗提出。假設現在有一個未知的函數,格羅弗演算法只需測試此未知的函數 次,其中
次,其中 為此未知函數的定義域的大小,即可以很高的概率找到一特定的輸入值,此輸入值能使此未知函數輸出特定的值。
為此未知函數的定義域的大小,即可以很高的概率找到一特定的輸入值,此輸入值能使此未知函數輸出特定的值。
同樣的問題在經典運算下,需要至少做  次測試(因為在最壞的情況下,可能第個定義域裏的值才是正確答案)。在格羅弗發表他的演算法前後,Bennett, Bernstein, Brassard, 和 Vazirani 在相近的時間證明了,任何量子演算法解決此問題都最少需要對此未知的函數做
次測試(因為在最壞的情況下,可能第個定義域裏的值才是正確答案)。在格羅弗發表他的演算法前後,Bennett, Bernstein, Brassard, 和 Vazirani 在相近的時間證明了,任何量子演算法解決此問題都最少需要對此未知的函數做  次測試,因此格羅弗演算法是漸進最佳的。[1]
次測試,因此格羅弗演算法是漸進最佳的。[1]
非局域隱變數量子計算機已經被證明可以在最多 ![{\displaystyle O({\sqrt[{3}]{N}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a953364313112d7f3243feb0c59146295a65263d) 步內實現在N個條目的數據庫裏的搜尋,這比格羅弗演算法的 還快,然而這些搜尋演算法並不能使量子計算機在多項式時間內解決NP-Complete 問題。[2]
步內實現在N個條目的數據庫裏的搜尋,這比格羅弗演算法的 還快,然而這些搜尋演算法並不能使量子計算機在多項式時間內解決NP-Complete 問題。[2]
不像其他的量子演算法可能會比相應的經典演算法有指數級的加快,格羅弗演算法二次方的加快,不過當很大時二次方的加快也相當可觀。格羅弗演算法可以在大約 264次迭代內窮舉破解一個128位元的對稱金鑰,在大約 2128次迭代內窮舉破解一個256位元的金鑰。因此,有人提倡對稱金鑰的長度應該加倍以因應未來的量子攻擊。[3]
像其他的量子演算法一樣,格羅弗演算法是概率性的,意味着這個演算法以小於1的概率給出正確答案。雖然實際上對於需要多少次重複才能給出正確的答案並沒有一個上界,但是期望的重複次數並不隨成長。在格羅弗發表此演算法的原始論文中稱此演算法為數據庫搜尋演算法,此說法至今仍普遍。此處數據庫相當於是一張存有未知函數的所有輸出值的表,以對應的輸入值為索引。
雖然格羅弗演算法的用處一直被認為是數據庫搜尋,但是它也可以被認為是函數取反。
考慮一個有N個元素的無序數據集,我們設函數 。我們假設,在所有的下標x中,有且僅有一個下標x有
。我們假設,在所有的下標x中,有且僅有一個下標x有 ,我們記這個下標x為
,我們記這個下標x為 ,並且稱為這個搜尋問題的解。而格羅弗演算法的目標便是找到下標。為此,我們構建一個酉算子
,並且稱為這個搜尋問題的解。而格羅弗演算法的目標便是找到下標。為此,我們構建一個酉算子 ,如下
,如下

或者可以簡寫為

事實上,我們一般構建另一種酉算子 ,如下所示
,如下所示

我們一般將作用在態向量和 的疊加態上,以實現相回傳(Phase Kickback),具體流程如下
的疊加態上,以實現相回傳(Phase Kickback),具體流程如下
![{\displaystyle {\begin{aligned}U_{f}|x\rangle |-\rangle &=U_{f}|x\rangle \left[{\frac {|0\rangle -|1\rangle }{\sqrt {2}}}\right]\\&={\begin{cases}{\frac {1}{\sqrt {2}}}(|x\rangle |1\rangle -|x\rangle |0\rangle )&{\text{for }}x=\omega \\{\frac {1}{\sqrt {2}}}(|x\rangle |0\rangle -|x\rangle |1\rangle )&{\text{for }}x\neq \omega \end{cases}}\\&=(-1)^{f(x)}|x\rangle |-\rangle \end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8796b53920ca58760d11f5aa441ed140f14ee614)
與一般的相比,使用了一個輔助的qubit。
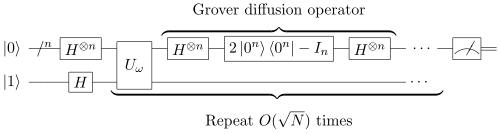 格羅弗演算法的量子電路表示
格羅弗演算法的量子電路表示
格羅弗演算法的步驟如下
- 構建量子疊加態

- 2. 做
 次「格羅弗迭代」,具體操作如下
次「格羅弗迭代」,具體操作如下
- 將作用在
 上
上
- 將
 作用在上
作用在上
- 其中,
 被稱為格羅弗擴散算子
被稱為格羅弗擴散算子
- 3. 測量,得到求得的結果
一般而言,的值會很大程度上影響得到正確結果的概率,且並不是越大得到正確結果的概率越大。分析表明最佳的有 ,因而格羅弗演算法的複雜度為
,因而格羅弗演算法的複雜度為
格羅弗演算法使用的技巧為振幅減枝(Amplitude amplification),實則是通過將其他態的振幅轉移為解的振幅,而是在測量時使得坍塌為解的概率增加。具體如下
考慮,我們將態向量改為以 為基,其中為解。寫作
為基,其中為解。寫作

在這種表示下,我們可以將和表示為
![{\displaystyle U_{s}:a|\omega \rangle +b|x\rangle \mapsto [|\omega \rangle \,|x\rangle ]{\begin{bmatrix}-1&0\\2/{\sqrt {N}}&1\end{bmatrix}}{\begin{bmatrix}a\\b\end{bmatrix}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e2f566230cbb5089c115d3a78124976c66273512)
![{\displaystyle U_{\omega }:a|\omega \rangle +b|x\rangle \mapsto [|\omega \rangle \,|x\rangle ]{\begin{bmatrix}-1&-2/{\sqrt {N}}\\0&1\end{bmatrix}}{\begin{bmatrix}a\\b\end{bmatrix}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d271061b669276655471fc0c72aab24928cf042a)

我們可以通過設 ,將上式覆寫為(所謂Jordan form)
,將上式覆寫為(所謂Jordan form)
 where
where 
作用r次則將得到

注意到,我們的目的是區別解以及其他一般的數據,而為了達到這個目的,我們使的振幅差別越大越好,換言之,要使得2rt和−2rt的差別足夠大,便有 , 或
, 或  . 這樣以來,就有
. 這樣以來,就有

作用在初始態上將會有
^{r}{\begin{bmatrix}0\\1\end{bmatrix}}\approx [|\omega \rangle \,|x\rangle ]M{\begin{bmatrix}i&0\\0&-i\end{bmatrix}}M^{-1}{\begin{bmatrix}0\\1\end{bmatrix}}=|\omega \rangle {\frac {1}{\cos(t)}}-|x\rangle {\frac {\sin(t)}{\cos(t)}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7619c5371b1e5120380587e8bfb86b10df9188e8)
簡短的計算表明,格羅弗演算法將具有 量級的誤差.
量級的誤差.


 . doi:10.1137/s0097539796300933. (原始內容存檔於2016-03-06).
. doi:10.1137/s0097539796300933. (原始內容存檔於2016-03-06).