在信息論中,夏農–菲諾–以利亞碼是算術編碼的先導,其機率被用於決定碼字。
給定一離散隨機變數 X ,令  為 X=x 發生之機率。
為 X=x 發生之機率。
定義

演算法如下:
- 對每個 X 中的 x,
- 令 Z 為
 之二次展開
之二次展開
- 令 x 之編碼長度

- 選定 x 之編碼,
 為
為  在 Z 之小數點後之第一個最高有效位。
在 Z 之小數點後之第一個最高有效位。
令 X = {A, B, C, D} ,其發生機率分別為 p = {1/3, 1/4, 1/6, 1/4} 。
- 對於 A

- 在二進位中, Z(A) = 0.0010101010...
- L(A) =
 = 3
= 3
- code(A) 為 001
- 對於 B

- 在二進位中, Z(B) = 0.01110101010101...
- L(B) =
 = 3
= 3
- code(B) 為 011
- 對於 C

- 在二進位中, Z(C) = 0.101010101010...
- L(C) =
 = 4
= 4
- code(C) 為 1010
- 對於 D

- 在二進位中, Z(D) = 0.111
- L(D) = = 3
- code(D) 為 111
夏農–菲諾–以利亞碼之輸出為二進位前綴碼,因此可被直接解碼。
令 bcode(x) 為二進位表示法最左側加入小數點而成之小數。舉例而言, code(C)=1010 ,則 bcode(C) = 0.1010 。 對所有 x ,如果沒有任何 y 存在使得

則所有的碼可構成前綴碼。
此性質可透過比較 F 和 X 之累積分布函數,以圖表示出:
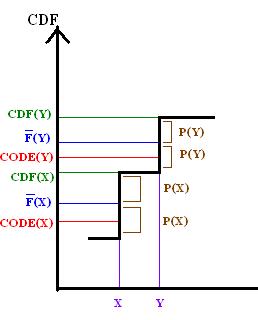
由 L 之定義可得

並且由於 code(y) 是由 F(y) 從 L(y) 之後的位元截短而得,故

因此 bcode(y) 必不比 CDF(x) 小。
上圖說明了  ,因此前綴碼定理成立。
,因此前綴碼定理成立。
此碼之平均長度為
 。
。
因隨機變數 X 之 熵 H(X) 滿足

夏農–菲諾–以利亞碼之長度約比代編碼資料之熵長約一到二額外位元,故甚少被實用。
T. M. Cover and Joy A. Thomas (2006). Elements of information theory (2nd ed.). John Wiley and Sons. pp. 127–128.


