
IDEF1X

信息建模集成定义(IDEF1X)是语义数据模型开发的数据建模语言。IDEF1X被用来产生一个图形信息模型,它表示在环境或系统中的信息的结构和语义[1] 。
IDEF1X允许的语义模型构造,足以支持管理数据为资源,信息系统集成,和建造计算机数据库。这个标准是软件工程领域的IDEF建模语言家族的一部分。
概述
[编辑]
数据建模技术用来以标准的、一致的和可预测的方式来建模数据,从而将它作为资源来管理。它在一个机构内可以用于要求定义和分析数据资源的标准手段的项目中。这种项目包括将数据建模技术结合入方法论,管理数据为资源,集成信息系统,或设计计算机数据库。IDEF1X的根本目标是支持集成。集成的方法聚焦于捕获、管理和使用被称为概念模式的一个数据资源的单一语义定义。
在1980年代早期开发最初的IDEF1X的时候,主导系统开发的世界观(view of the world)是以数据和过程作为框架。这种数据/过程(D/P)范型(paradigm)的建模方法被归结为:
- 世界由活动和事物构成。
- 事物是集成的。活动是独存的(free-standing)。
- 活动操作在事物上。
在这种方法中,信息建模技术的主要目标是:
- 提供理解和分析一个机构内数据资源的方式。
- 提供表示和推理数据的通用方式。
- 提供体现运行一个企业所需数据的总体视图的方法。
- 提供定义可被用户检验并转化成物理数据库设计的不依赖于应用的数据视图的方式。
- 提供从现存数据资源导出集成数据定义的方法。
D/P范型对信息技术的所有方面施加了强大和普遍的影响。对于IDEF的结果是产生了两种不同的技术:IDEF0用于过程而IDEF1X用于数据。使用D/P世界观已经开发出了数以千计的成功系统,很多开发者继续成功的采用着这种技术。IDEF1X97(IDEFobject)采用了面向对象(OO)的世界观。
历史
[编辑]在1970年代中期美国空军在集成计算机辅助制造(ICAM)规划中认识到了对语义数据模型的需要。这个规划的目标是通过计算机技术的系统应用增进制造生产力。ICAM规划确认了在增进制造生产力中所涉及到的人们需要更好的分析和交流技术。作为结果,ICAM规划开发了叫作IDEF(ICAM定义)方法的一系列技术,包括如下[1]:
- IDEF0,用来产生“功能模型”,它是在环境或系统中活动或过程的结构表示。
- IDEF1,用来产生“信息模型”,它表示在环境或系统中的信息的结构和语义。
- IDEF2,用来产生“动态模型”,它表示在环境或系统中随时间变化的行为特征。
IDEF信息建模(IDEF1)的最初方法由ICAM规划在1981年发表,基于了当年的研究和工业需求[2]。这种方法的理论根源来自Edgar F. Codd在关系模型理论上和Peter Chen在实体联系模型上的早先工作。最初的IDEF1技术基于了休斯飞机公司的Dr. R. R. Brown和Mr. T. L. Ramey和D. Appleton公司(DACOM)的Mr. D. S. Coleman的工作,有着Charles Bachman、Peter Chen、Dr. M. A. Melkanoff和Dr. G. M. Nijssen的关键评论和影响[1]。
在1983年,美国空军发起了在ICAM规划之下的集成信息支持系统(I2S2)计划。这个计划的目标是提供一种技术,能够在逻辑上和物理上集成异构计算机硬件和软件的网络。这个计划和工业实验的结果是,认识到了对信息建模的增强技术的需求[1]。
从空军IDEF规划的合同管理的视角看来,IDEF1X是ICAM IISS-6201计划的结果并由IISS-6202计划进一步的扩展了。为了满足IISS-6202计划确定的数据建模增强要求,子承包商DACOM,获取了逻辑数据库设计技术(LDDT)和它的支持软件(ADAM)的许可证。从建模技术的技术内容视角看来,IDEF1X是重命名了的LDDT。
LDDT是数据库设计组(DBDG)的Robert G. Brown在1982年设计的,他完全在IDEF规划之外并且不知情IDEF1。然而IDEF1和LDDT的中心目标是一致的。LDDT基于了关系模型、实体联系模型和J. M. Smith与D. C. P. Smith的数据泛化(generalization)概念。LDDT的图形语法不同于IDEF1,并且更加重要的是,LDDT包含很多不出现于IDEF1的相互联系的建模概念。因此不再扩展IDEF1,DACOM的Dr. Mary E. S. Loomis使用尽可能兼容于IDEF1的术语,写了一份LDDT的实质子集的语法和语义的简要总结。DACOM将结果标记为IDEF1X(扩展的IDEF1)并提交给了ICAM规划,它在1985年将其发表[3][1]。
在1993年1月DBDG的Robert G. Brown完成了IDEF1X形式化。他得到了多次草案所受评论的帮助,评论者包括:Tom Bruce、Ben Cohen、Dave Brown、Twyla Courtot、Chris Dabrowski、Jack Boudreaux、Dan Spar和Mary Loomis。在1993年12月,美国政府发行了IDEF0标准(联邦信息处理标准刊物183即FIPS 183)和IDEF1X标准(FIPS 184),并由国家标准技术研究所(NIST)来维护[4]。
IEEE Std 1320.2-1998继续了IDEF1X语言的演化。最初的工作由DBDG的Robert G. Brown在1994年和1995年早期为NIST完成,对IDEF1X向完全覆盖的对象建模的优雅进化,提供了所需要的基本元素。这个标准描述了IDEF1X97(IDEFobject)的语法和语义,它由两个概念建模语言组成:一个“键风格”语言后向兼容FIPS 184,它支持关系数据库和扩展关系数据库,和新的“标识风格”语言,它适合于对象数据库和面向对象建模[5]。
在2008年9月2日,有关的NIST标准FIPS 183和FIPS 184被撤销。自从2012年9月,IDEF0和IDEF1X97(IDEFobject)一起成为ISO/IEC/IEEE国际标准,在2019年二者被确认仍是当前标准[6]。
IDEF1X语法和语义
[编辑]-
 实体语法
实体语法 -
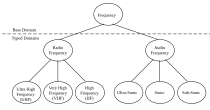 域层级
域层级 -
 联系的势语法
联系的势语法 -
 未明确联系语法
未明确联系语法




- 实体(entity)
- 实体表示真实或抽象的事物(人、物体、处所、事件、想法、事物的组合等)的集合,这些事物由于共享着相同的特征并可以参与相同的联系,从而被识别为同一类的实例。
一个实体是“独立标识符”(identifier-independent)实体,如果这个实体的每个实例都可以唯一的标识出来,不用确定它的到其他实体的联系。一个实体是“依赖标识符”(identifier-dependent)实体,如果这个实体的实例要唯一的标识出来,得依赖于它的到其他实体的联系。
在实体联系模型中,将不能单独用自身特性唯一的标识出来的实体称为弱实体;有两种类型的弱实体:关联实体和子类型实体,子类型实体基于超类型实体的鉴别器(discriminator)的值来继承它的特性。
- 类(class)
- 人们在心智上将在某种意义上类似的事物归类(classify)入一个类,以此意义(sense)命名并表示所有这种类似的事物。所有人都做这种归类,这是常理的一部分。以这种方式归类的事物是个体的事物,每个都明显不同(distinct)于所有其他事物。
在IDEF1X97中,一个类是一组类似事物的知识(数据)和行为(过程)的抽象。状态类表示具有可变更的状态的那些实例。实体对应于只有特性属性的状态类。依赖状态类是其实例就本性而言,内在的有关于特定的其他状态类的实例的状态类。独自拥有一个依赖状态类的实例而无关于另一个状态类的一个实例是不适当的,进一步的说,更换与其有关的实例是没有意义的。独立状态类是并非依赖状态类的状态类。
归类入一个类的任何事物都被称为这个类的一个实例。每个实例都被认为有一个唯一的、内在(intrinsic)的标识(identity),无关于它的属性(property)值或它所归属的类。一个实例的唯一标识将它区分于所有其他实例。
在IDEF1X97中,对于状态类,对象标识符(oid)表示了标识的概念。就一个表示系统(例如例子、形式化或软件)而言,oid代表了实例。在状态类实例的样本实例表中,每一行都有一个关联的oid。注意oid不是特性,oid对客户总是隐藏的。数据库中的代理键(surrogate key)是在所建模世界中实体实例亦或数据库中对象的唯一标识符。代理键不导出自应用数据,而导出自应用数据的键称为自然键[7]。
- 域(domain)
- 域是具有相同数据类型的(固定的或可能无限数目的)数据值的命名集合,特性实例从其中取得实际值。域可被当作不可变值的类,它包含的值不随时间改变。在IDEF1X97中,域被称为值类。
所有特性都必须恰好的定义在一个底层域之上。多个特性可以基于相同的底层域之上。类型(typed)域是基础类型或其他类型域的子类型,它可以进一步的约束这个域的可接受的值。一个类型域存在,如果它具有数据类型,并且满足它的超类型域的域规则。可以按这种方式定义域的层级,从层级自上而下具有更加紧缩的域规则。域层级是泛化层级,不同于实体的分类结构,这里不含摄域子类型要相互排斥。
在关系数据库中,要求各种表的所有列都声明在一个定义了的域之上被称为域完整性约束。关系模型中的主要数据单元即数据项是不可分解或原子性的。

- 联系(relationship)
- 联系是在两个实体的实例之间或相同实体的实例之间的关联(association)。联系的势(cardinality)是在一个联系中一个实体的可以相互关联的实例数目。在联系上可以指明特定的势约束,实体的实例在一个联系中通常有四种类型中的一种势:极小0极大1,极小0极大不限,极小1极大1,极小1极大不限。
在实体联系模型中,实体的一个或多个实例参与(participate)一个单一的联系,联系对应于这些实体的数学关系,最常见的是两个实体间的二元关系,例如一个实体的一个实例和另一个实体的n个实例参与的一个单一的联系,对应n个有序对构成的二元关系。对于在集合X和集合Y上的二元关系R[8]:- 左唯一(left-unique)也称为内射(injective):对于所有y∈Y存在最多一个x∈X使得xRy。这等价于:对于所有x∈X,所有z∈X,所有y∈Y,如果xRy且zRy,则x=z。这里的集合Y叫作二元关系R的主键[9]。
- 右唯一(right-unique)也称为泛函(functional):对于所有x∈X存在最多一个y∈Y使得xRy。这等价于:对于所有x∈X,所有y∈Y,所有z∈Y,如果xRy且xRz,则y=z。这里的集合X叫作二元关系R的主键[9]。
- 左全体(left-total)也称为序列(serial):对于所有x∈X存在最少一个y∈Y使得xRy。
- 右全体(right-total)也称为满射(surjective):对于所有y∈Y存在最少一个x∈X使得xRy。
- 通过唯一性性质,可以定义出特殊类型的二元关系:一对多,内射且非泛函;多对一,泛函且非内射;一对一,内射且泛函;多对多,非泛函且非内射。通过唯一性和全体性性质,可以定义函数为泛函且连续的二元关系,进一步的定义出内射函数、满射函数和双射(bijective)函数。
- IDEF1X限制为只使用二元联系,因为它们比多元联系易于定义和理解,还有直接的图形表示。缺点是在表示多元联系时必然显得笨拙,但是不会有能力上的损失,因为任何多元联系都可以使用多个二元联系来表达。
- 存在依赖(existence dependency)
- 存在依赖是在两个有关的实体之间的约束,指出一个实体(子实体)的实例不能存在却无关于另一个实体(父实体)的实例。下述联系类型中,标识联系、强制非标识联系和分类联系体现了存在依赖。
- 未明确(non-specific)联系
- 未明确联系表示两个实体之间的多对多联系,其中任何一个实体的实例都可以关联于另一个实体的任何数目的实例。为了解决未明确联系而介入的实体有时叫做交叉(intersection)实体或关联实体。
-
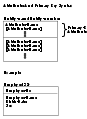 特性和主键语法
特性和主键语法 -
 替代键语法
替代键语法 -
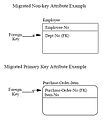 外键语法
外键语法 -
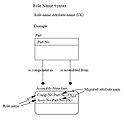 角色名字语法
角色名字语法




- 特性(attribute)
- 特性是共同于一个实体的某些或所有实例的一个属性(property)或特征。特性表示域在一个实体的上下文中的使用。
实体的特性通常要满足一组规范化理论约束,即关系模型中的第一范式、第二范式和第三范式。实体的实例对这个实体关联的特性不可给与多于一个的值,这个规则被称为不重复(no-repeat)规则。
- 主键(primary key)
- 主键是已选择为一个实体的唯一性标识的候选键。其他候选键则成为替代键(alternate key)。组成主键的那些特性都不能有空值。主键和替代键必须只包含对唯一性标识作出贡献的那些特性,具有复合主键的实体必须不能够拆分成具有更简单主键的多个实体,这个规则叫做最小键规则。
函数依赖是其应用局限在一个单一实体之内的一种特殊的完整性约束,这个实体的特性“X”的每个值都有与之相关联的最多一个它的特性“Y”的值(在任何一个时刻),特性“X”和“Y”可以是复合的,特性“Y”函数(functional)依赖于特性“X”。如果主键由多于一个特性组成,则每个非键(nonkey)特性的值必须函数依赖于整个主键,这个规则叫做完全函数依赖规则。不是主键或替代键的一部分的所有特性,必须只函数依赖于主键和每个替代键,这个规则叫做无传递依赖规则。
在关系数据库中,要求确保表的每行都有唯一且非空的主键值被称为实体完整性约束。每个替代键都可以指定唯一约束。
- 外键(foreign key)
- 外键是子或分属(category)实体实例的一个特性或特性组合,它的值匹配于有关的父或总属(generic)实体实例的主键中的值。在外键中的特性或特性组合可以指派一个角色(role)名字,反映在子或分属实体中它的角色。
外键可以被看作父或总属实体的主键通过明确(specific)的联结联系或分类联系“迁移”而来的结果。迁移来的特性可以被用作实体的要么全部的主键要么主键的一部分、替代键或非键特性。如果一个子实体有到同一个父实体的多个联系,则在子实体中为每个联系都迁移一次父实体的主键特性。
如果父实体的所有主键特性都被迁移为子实体的主键的一部分,则这个联系叫作"标识联系"。如果有任何的迁移来的特性不是子实体的主键的一部分,则这个联系叫作“非标识联系”。当一个迁移来的主键只有一部分特性成为子实体的主键的一部分,而余下的特性成为子实体的非键特性的时候,这个非标识联系促成的外键叫作“分裂键”。在分类联系中,所有分属实体的主键都是通过这个联系从总属实体迁移来的。
在关系数据库中,通常要求外键等于主表中的某行的候选键,或者没有值即有空值[10],这个规则叫做两个表之间的参照完整性约束。在参照或子表中的多个行可以涉及在被参照或父表中的相同行。在这种情况下,在被参照表和参照表之间的联系是一对多联系。
- 标识符依赖(identifier dependency)
- 标识符依赖是在两个有关的实体之间的约束,要求一个实体(子实体)中的主键包含另一个实体(父实体)的整个主键。下述联系类型中,标识联系和分类联系体现了标识符依赖。
-
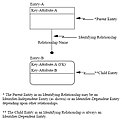 标识联系语法
标识联系语法 -
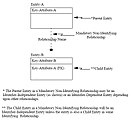 强制非标识联系语法
强制非标识联系语法 -
 可选非标识联系语法
可选非标识联系语法 -
 分类联系语法
分类联系语法




- 联结(connection)联系
- 联结联系也叫做父子联系,有明确的势定义。它是在两个实体之间的关联或联结,其中被称为父实体的一个实体的每个实例,都关联于被称为子实体的另一个实体的零个、一个或多个实例。
联结联系分为子实体为“依赖标识符”实体的标识(identifying)联系,和子实体为“独立标识符”实体的非标识(non-identifying)联系。在强制(mandatory)非标识联系中,子实体的每个实例都恰好的关联于父实体的一个实例。在可选(optional)非标识联系中,子实体的每个实例关联于父实体的零个或一个实例。
在标识联系和强制非标识联系中,子实体总是存在依赖于父实体。可选非标识联系表示有条件的存在依赖。其中此联系的每个外键特性都有一个值的子实体的实例,必须有关联的父实体实例,其中此父实体实例的主键特性在值上等于子实体实例的外键特性。
- 分类(categorization)联系
- 分类联系是其中两个实体的实例表示相同的真实或抽象事物的联系。一个实体(总属实体)表示这个事物完全集合,另一个实体(分属实体)表示这种事物的一个子类型或子分类。分属实体可以有一个或多个特征,或与其他实体的实例的联系,不共享于所有的总属实体实例。
分类簇(category cluster)是一个或多个分类联系的集合。总属实体的一个实例可以关联于这个簇里分属实体中只有一个实体的实例,而分属实体的每个实例都恰好的关联于总属实体的一个实例。因为总属实体的一个实例在分类簇中不能关联于多于一个分属实体的一个实例,分属实体是相互排斥的。在总属实体或它的一个前辈实体中的一个特性,可以被指派为这个实体的特定分类簇的鉴别器。
在完备(complete)分类簇中,总属实体的所有实例都关联于一个分属实体的一个实例,也就是说所有可能的分类都出现了。在不完备(incomplete)分类簇中,总属实体的一个实例可以存在却不关联于任何分属实体的一个实例,也就是说某些分类被省略了。
分类结构是广泛化/特殊化构造。在增强实体联系模型中,子类型实体和超类型实体之间是一种Is-a联系。在IDEF1X中,子类型联系按分类实体集合是否完备而分为完备子类型联系和不完备子类型联系。
- 视图(view)
- 视图是为了某种用途而组装的实体和指定的特性(域)的一个搜集。IDEF1X中定义了三种层次的视图:实体联系(ER)、基于键(KB)和全特性(FA)。它们在抽象层次上有所不同。ER层次是最抽象的,它建模主题领域中最基础元素,即实体和它们的联系,它在作用范围上比其他层次要更宽广。KB层次增加键,而FA层次增加所有特性。
功能视图是构造用来显示所建模企业某方面功能有关的数据结构的视图框图。
IDEF1基本概念回顾
[编辑]
IDEF1X使用的术语非常类似于IDEF1,二者采用的理论基础和概念却有着根本的差异。实体在IDEF1中表示在一个特定机构内维持的关于物理或概念对象(比如人、处所、事物或想法)的信息。术语实体类在IDEF1中指称实体的搜集,或保管的关于真实世界中对象的信息的类。实体类可以被想象为是存放3英寸×5英寸卡片的盒子,每个卡片都是实际的实体。盒子外面标记着:⑴描述盒子中有何种类型的卡片的一个实体类名字,⑵向最终放进来的单个卡片提供的一个模板(template)。
实体拥有关联的特征特性,用来记录真实世界中对象的属性。使用卡片档案(card file)模型,特性类是向在这些单个档案卡片中找到的特性-值对提供的模板。术语特性类指称特性-值对的集合,这是通过将在档案盒子外面找到的特性的名字,和列出在这些单个卡片自身上的、对于单个实体类成员(实体)的这个特性的值,组合起来形成的。键类是一个或多个特性的一个搜集,凭借它就可将卡片或实体类成员相互区分开来。键类通过放置到模板的左上角并加以下划线来指示。
关系(relation)在IDEF1中是在两个单个的信息映像(image)之间的关联。这种参照的存在,是通过注意到一个实体类的这些特性类,包含了被参照的实体类成员的键类的那些特性类而发现(或验证)的。一个关系类可以被想象为是向实体类之间存在的关联提供的模板。需要注意到一个要点,如果关于两个或多个真实世界中对象之间的关联没有保管信息,那么从IDEF1的视角看来就不存在关系。关系类在IDEF1框图中表示为在实体类盒子之间的链接(link)。在链接端部的菱形和在链接中部的半菱形,编码了关于关系类的额外信息(就是势和依赖)。这些链接经常指示出一个机构的业务规则的存在。
同IDEF1X有关的底层概念,意图将关于真实世界事物的自然语言事实的建模,桥接于逻辑数据结构的建模。这相当不同于IDEF1的目标,它严格关注于真实世界事物的信息映像(不是事物自身,也不是表示关于事物的信息的数据结构)。
来自最初ICAM工作的概念和过程
[编辑]三模式方法
[编辑]
在软件工程中,三模式方法是建造信息系统和系统信息管理的方法,提倡概念模型作为完成数据集成的关键[12]。
模式(schema)是一种模型,通常描绘为框图并且有时还结合语言描述。这个方法用的三个模式是[13]:
- 用于用户视图的外部模式。
- 集成外部模式的概念模式。
- 定义物理存储结构的内部模式。
位于中心的概念模式,定义用户所思考和谈论的概念的本体。物理模式描述在数据库中存储的数据的内部格式,而外部模式定义应用程序表现出的数据的视图[14]。这个框架尝试将多个数据模型用于外部模式[15]。
概念模式提供一个企业内数据的一种单一的集成定义,它不偏向于数据的任何单一应用,并且不依赖于数据在物理上如何存储和访问。概念模式的主要目标是提供对数据的含义和相互关系的一种一致性定义,它可以被用于集成、共享和管理数据的完整性。概念模式必须有三个重要特征[1]:
- 一致于业务的下部结构并跨越所有应用领域都是真实的。
- 是可扩展的,使得新数据可以定义而不需更改以前定义的数据。
- 可转化成需要的用户视图和各种数据存储及访问结构二者。
建模指南
[编辑]建模过程可以分成模型开发的五个阶段。
- 零阶段 – 项目初始
- 项目初始阶段的目标包括:
- 项目定义:一般陈述已经做了什么、为什么要做和怎样做。
- 来源材料:获取来源材料的规划,包括索引和文件归档。
- 作者约定:约定(和可选的方法)的基础声明,作者选择它们用来制作和管理这个模型。
-
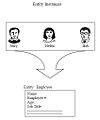 综合出一个实体
综合出一个实体 -
 实体联系矩阵
实体联系矩阵 -
 实体层次框图例子
实体层次框图例子 -
 聚焦一个单一实体的“实体框图”
聚焦一个单一实体的“实体框图”



_Diagram_Example.jpg)
- 第一阶段 – 实体定义
- 实体定义阶段的目标是标识和定义属于要建模的问题领域的实体。实体是从基本实体实例综合出来的结果,这些实例成为这个实体的成员。第一阶段的产出是:
- 实体池。实体池包含在此刻已知模型的上下文内的所有实体的名字。在第四阶段结束时,这个列表中的一些名字很有可能不能存留为实体。此外随着建模的前进和信息理解的增进,一些新的实体将被增加到这个列表并成为这个信息模型的一部分。
- 实体术语表(glossary)。在这个阶术语表只是实体定义的一个搜集。一个实体定义的构件包括:实体名字,实体定义和实体别名。
- 第二阶段 – 联系定义
- 联系定义阶段的目标是标识和定义在实体之间的基本联系。在建模的这个阶段,一些联系可以是未明确的并且需要在后续阶段来精制。从这个阶段主要的输出是:
- 联系矩阵。要识别在各种实体之间观察到联系,可能要求开发一个实体的联系矩阵来指示出所有可能的实体之间的联系。
- 联系定义。这些定义包括:依赖的指示,联系名字,和关于联系的叙事陈述。作为规定联系的结果,可能还会抛弃一些联系和增加新的联系。
- 实体层次框图。在建模的这个阶段,所有实体都展示为方框并允许未明确联系。
-
 特性实例和它们分别的实体实例
特性实例和它们分别的实体实例 -
 未明确联系精制
未明确联系精制 -
 对键特性应用不重复规则精制
对键特性应用不重复规则精制 -
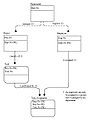 用来去除多余联系的路径断定
用来去除多余联系的路径断定




- 第三阶段 - 键定义
- 键定义阶段的目标是:
- 精制来自第二阶段未明确联系。精制联系的过程将每个未明确联系转化或转换两个明确联系,为此演进出新的实体。
- 定义每个实体的键特性。标识键的过程包括:标识出一个实体的候选键,选择一个候选键作为这个实体的主键,标记这个实体的替代键。本阶段结束时产出键特性定义。特性定义包含:特性名字,特性定义和特性别名。
- 迁移主键来建立外键。有三个规则支配这个过程:在一个联系中迁移总是发生于从父或总属实体到子或分属实体,整个主键(就是这个主键的所有成员特性)对这个实体对共享的每个联系都必须被迁移一次,非键特性永不被迁移。
- 验证联系和键。应用各种规则对模型进行精制。通过路径断定去除多余的联系。随着主键成员被标识出来,涉及过的特性形成一个特性池。使用实体/特性矩阵来标识整个模型中特性的分布和使用。
-
 实体/特性矩阵
实体/特性矩阵 -
 第三阶段功能视图框图的例子
第三阶段功能视图框图的例子 -
 对非键特性应用不重复规则精制
对非键特性应用不重复规则精制 -
 第四阶段功能视图的例子
第四阶段功能视图的例子




- 第四阶段 - 特性定义
- 特性定义阶段的目标是:
- 开发特性池。扩展第三阶段建立的特性池来包含非键特性。特性池是潜在可行的特性名字的一个搜集,是在这个模型中用到的特定名字的来源。
- 确立特性从属。这一步为每个非键特性指定一个所属实体。
- 定义非键特性。特性定义包含:特性名字,特性定义和特性别名/同义词。
- 验证和精制数据结构。应用各种规则对模型进行精制。
形式化
[编辑]
形式化(formalization)的目的,是通过向IDEF1X的每个建模构造,提供到形式的一阶语言中的一组等价句子的映射,精确的陈述这些构造意味着什么。图形语言可以被当作表达等价形式句子的实际的简洁方式。
IDEF1X结合了关系模型、实体联系模型和数据泛化的元素。增加了视图、术语表(glossary)和模型层级的想法,来解决实际中遇到的那种规模的问题。结果是IDEF1X的形式化,不能严格的只依据关系模型,而是直接使用一阶逻辑。为了增进形式化的能用性,只使用逻辑的有限子集,本质上为入门教程所涵盖。
一部分的形式化依托于IDEF1X的元模型。形式化中解释(interpretation)所指定的关系,可以非正式的看作在IDEF1X中使用的常见的样本实例表。建模构造的形式句子,可以非正式的看作在这些实例表上的初步的查询语言。元模型、实例表和查询语言仅凭视角(points of view)自身就是有用的,不依赖于详细的形式化。
形式化预期向依靠IDEF1X构造的含义的如下领域提供坚实基础,如SQL或其他代码生成,与其他建模方式来回转化,与其他种类的模型集成,像静态属性一样捕获动态属性。这些领域都要求形式化提供的严格定义的语义。
IDEF1X理论
[编辑]IDEF1X模型构成自(比如以框图、语言或表格表达的那些实体、特性和联系的)一个或多个视图,加上一组术语定义,至少包括这些视图(直接或间接)用到的全部的实体和域。形式化处理过程产生相应的一阶逻辑中的理论。
一阶逻辑可以被当作是自然语言的用来描述和推理事物的那些方面的形式语言版本。个体事物使用常量、变量和函数符号来指称;在事物之间的关系使用谓词符号来陈述;而关于事物联系的句子通过逻辑联结词比如与、或、非,和全称(for all)及存在(for some)量词来陈述。
一阶逻辑理论构成自其中常量、函数和谓词符号被限定于特定词汇表(vocabulary)的一阶逻辑的语言,加上这个语言中的一组句子(叫做公理)。IDEF1X理论的起点是带有等式的一阶逻辑,假定已有整数和列表的理论的词汇和公理。补充的IDEF1X的词汇和公理来自如下本质想法:
- 每个有
n个特性的实体类都变成一个n+1元谓词符号。
- 这个谓词将一个实体实例关联上它的特性值。如果有
2个特性的一个实体类被表示为3元谓词符号p,它的第1个特性是a1,第2个特性是a2,则p(I, A1, A2)意味着,标识为I的个体是这个实体类的成员,并且作为这个类的成员,有一个a1特性值A1,和一个a2特性值A2。如果A1(或A2)是空,这意味着I(所标识的个体)没有给a1(或a2)特性的值。
- 每个联系都变成一个二元谓词符号。
- 这个谓词将父实体的实例(的标识)关联上子实体的实例(的标识)。如果这个联系被表示为二元谓词符号
r,则r(I, J)意味着,I(所标识的个体)是J(所标识的个体)的父亲。
- 定义了谓词
exists来说明一个实体或域实例是否存在。
- 注意
exists不是存在量词。exists C: I意味着,C: I是一个存在的实体(或域)类实例。在这里如果C是一个实体类,则I是一个实体标识符,如果C是一个域类,则I是一个表示(representation)值。注意术语C: I只是提名某个事物可以是一个类实例。C: I事实上是一个存在的类实例,当且仅当exists C: I成立。
- 定义了谓词
has来说明一个实体实例,是否持有特定的特性值,或者关联于特定的其他实体实例。
C: I has P: V意味着,实体类实例C: I,持有属性P的值,并且这个值是V。属性(property)P,可以是一个特性(attribute),或一个参与(participant)属性。如果P是特性,则值V是域实例。参与属性引起自联系,在一个联系中的每个实体,都为与其有关联的实体实例持有一个参与属性,如果P是一个参与属性,则值V是有关联的实体实例(的标识符)。
- 规则(这个理论中的公理)使用约束实体、域和联系的谓词
exists和has来书写。
- 不直接使用底层的
n元和二元谓词,转而依据类实例的存在性和这些实例的属性值,来表达IDEF1X建模构造的形式含义。用exists和has书写的句子,可以被非正式的当作对样本实例表的初步的查询语言。
IDEF1X所建模的是一个企业所关心的事物,不是这些事物的名目,也不是关于这些事物的数据,一个IDEF1X模型预期成为这个企业所关心的事物的概念模型。这种论域UOD(universe of discourse)在它的模型之外有独立的存在和现实。在任何时间点上,UOD都处在特定状态(state)下,就是说有特定的实体实例存在,它有特定的属性值,并拥有特定的与其他实体实例的联系。对于任何UOD状态,一些句子是真的,而另一些句子是假的。一些UOD状态是可能的,另一些是不可能的。关于UOD的句子是真还是假,不依赖于它的任何模型。
一个IDEF1X模型被认为是正确的,如果它以相关(relevant)的方式匹配UOD。一个正确的IDEF1X模型允许所有可能的UOD状态,并拒绝所有不可能状态,它们直接冲突于这个模型的显式断言。换句话说,一个IDEF1X模型是正确的,如果它坚持为真的句子(公理),事实上在所有可能UOD状态下是真的,在所有不可能状态下是假的。
真实是依据解释来定义的。一个解释将来自UOD的元素指定(assign)给这个理论的符号。特别是,一个解释将某一个关系指定给每个谓词符号。作为结果,在理论中的句子变成关于UOD的句子,并且它们的真实要依据UOD的现实来确定。以这种方式,每个句子在这个解释中要么是真要么是假。一个解释被称为一个理论的“模型”,如果这个理论的所有公理在这个解释中都是真的。一个IDEF1X模型是正确的,当且仅当对应于它的理论,仅拥有所有的将可能的UOD状态指定给这个理论的符号的那些解释作为“模型”。
在形式化中,一个实体类(或联系)成为一个谓词符号。在逻辑中,一个解释将一个关系指定给这个谓词符号。在预期解释中,针对一个IDEF1X模型的UOD构成自:视图、实体、域、域实例、视图实体、视图实体实例,视图联系、视图联系实例、视图实体特性和视图实体特性值。这些在IDEF1X中都非正式的用样本实例表来展示。非正式的实例表是对指定给谓词符号的形式关系的一种表示。在形式化的语境中,样本实例表展现了一个(可能的)UOD。在示例的样本实例表的左侧的iN表示被归类为是对应于这个表的实体类的成员的一个“事物”的标识。
IDEF1X元模型
[编辑]
IDEF1X可以被用来建模IDEF1X自身。这种元模型有多种用途,比如仓库(repository)设计、工具设计或用于规定有效的IDEF1X模型的集合。依赖于用途,会得到略微不同的模型。对元模型有两个重要的限制。首先它们规定语法而非语义。其次元模型必须补充采用自然或形式语言的约束。IDEF1X的形式理论提供了表达所需约束的语义和方式二者。
IDEF1X标准在规定了IDEF1X模型到一阶理论的映射之后,定义了IDEF1X元模型。在这个模型上的约束使用一阶语言来表达。这些约束成为这个元模型的IDEF1X理论的一部分。一个有效的IDEF1X模型接着被定义为这个元模型的IDEF1X理论的“模型”。
IDEF1X97的概念
[编辑]面向对象(OO)世界观的涌现已经严重影响了IDEF1X的演变。对象范型采用了根本上不同的世界观。在这个范型中,建模方法可以归结为:
- 世界构成自对象。
- 对象具有知识和行为。
- 没有独存(free-standing)的活动。活动是通过对象的协作完成的。
- 知识和行为是在责任(responsibility)抽象后面的,在一起考虑的,同一对象的不同方面(aspect)。
这种方式中,建模技术的主要目标是:
- 提供理解和分析一个机构关切的对象的方式。
- 提供表示和推理这些对象的通用方式。
- 提供体现运行一个企业所需的对象的总体视图的方法。
- 提供定义可被用户检验并转化成物理设计的不依赖于应用的对象视图的方式。
D/P和OO范型的方式是不同的。对于IDEF1X,从D/P和OO方式涌现出来的概念不是完全不兼容的,实际上概念有高度的对应性。
| 数据/过程范型假定 | 面向对象范型假定 | 对比 | |
|---|---|---|---|
| 实例 | 实体实例是一个企业需要为其保管数据的人、处所或事物(等)。 | 对象是具有相关的知识(数据)或行为(过程)的与众不同(distinct)的事物。 | 对象合并了数据和过程(知识和行为)并将它们隐藏在责任抽象的后面。 |
| 数据 | 没有独存的数据。所有数据都围绕着共享的一个企业的真实世界实体而组织。数据是通过过程来访问的并遍及应用共享的。 | 没有独存的知识(数据)。所有知识都围绕着共享的一个企业的真实世界对象而组织。知识对遍及应用的其他对象是通过请求而可获得的(和可修改的)。 | 在D/P范型中,过程直接访问并改变一个实体的数据。在OO范型中,必须向一个对象请求它的知识,它的知识不是可以直接访问的。只有对象自己可以改变它的知识。一个对象的知识是来自记忆还来自推导只有这个对象知道。 |
| 过程 | 过程是独存的。过程是围绕功能来组织的,过程访问实体并独一于一个应用。 | 没有独存的行为(过程)。所有行为都围绕着共享的一个企业的真实世界对象而组织。行为是对象的责任,并且对遍及应用的其他对象是通过请求而可获得的。 | 在OO范型中,所有过程都通过对象的行动来完成。一个对象通过利用自己和经过请求利用协作对象的知识和行为来行动。对一个请求确切的做了什么只有这个对象知道。 |
| 类 | 类似的实体实例被归类入类,而类通过聚集和广泛化关联起来。 | 类似的对象(实例)被归类入类,而类通过聚集和广泛化关联起来。 | 本质上相同的想法,除了对象类包括行为之外。 |
| 标识 | 一个类中每个实体实例都通过它的数据值来区别于所有其他实例。 | 每个对象都不同于所有其他对象。它有着内在的、不可变的标识,不依赖于它的知识、行为或类。 | OO模型能够将被D/P范型当作不可区分的东西识别为不同的。 |
| 约束 | 有在数据上的约束。 | 有在知识和行为二者上的约束。 | 对象模型需要更一般种类的约束。 |
| 规则 | 规则是通过定义支持它们的过程而并入的。 | 规则是通过定义支持它们的行为而并入的。 | D/P和OO范型在这点上都是可以改进的。如果规则可以解脱于行为就更好了。 |
IDEF1X97的构造
[编辑]IDEF1X97的语言构造包括:
- 类
- 类是一组类似的事物的知识和行为的抽象。被归类入一个类的任何事物都被称为这个类的实例。给定类的所有实例都有相同的责任。就是说它们拥有相同种类的知识,展现相同种类的行为,服从相同种类的规则。实例是离散的,它给事物绑定上一个内在的、不可变的和唯一的标识。
- 每个类要么是状态类要么是值类。
- 状态类。状态类表示带有可变更状态那些实例。它的实例可以有来往(come and go)并随时间而改变,就是说它们的属性值可以变更。
- 值类。值类表示纯值的那些实例。它的实例不可来往并不可变更。
- 泛化
- 类被用来表示“具有相关的知识或行动的那些事物”的概念。由于一些真实世界事物是其他真实世界事物的广泛化,一些类必须在某种意义上是其他类的广泛化。向更一般性的一个类指定了增补的、不同的责任的一个类,叫做这个更一般性的类(它的超类)的子类。这个子类的每个实例都表示与它的超类中的实例相同的真实世界事物。类结构作为一个广泛化分类法(层级或网络),确定在这些类之间的责任继承。
- 联系
- 联系表达在两个状态类之间的联结,它被视为相关于特定的范围和用途。它以这些实例据此而有关的那种意义来命名。
- 责任
- 一个实例拥有知识,展现行为,服从规则。这些概念在集体上的被称为这个实例的责任。一个类抽象了共同于它的实例的责任。在最初的模型开发期间,责任可以简单的用一般性术语来陈述,并且不明显的区分为特性、参与属性、操作或约束。还可以指定聚集(aggregate)责任,而非个体属性。宽泛陈述的责任最终被精制为特定的特性和约束。
- 属性。一些责任由知识和行为来承担,而它们顺次由属性来确定。属性是显露一个对象的知识或行为的某些方面的,固有(inherent)的或独特的特征或特质(trait)。有三种属性(property):特性(attribute)、源于联系的参与(participant)属性和运算(operation)。类拥有属性,实例拥有属性值。
- 特性。特性是从一个类到一个值类的映射。一个特性表达一般共同于一个类的那些实例的一些特征。特性的名字是这个值类在描述这个类时所扮演的角色的名字,它可以简单的是这个值类的名字(只要使用值类名字不导致歧义)。
- 参与属性。参与属性是从一个状态类到一个有关的(不必须不同的)状态类的映射。当在两个状态之间存在联系的时候,每个类都为这个联系包含一个参与属性。每个参与属性的名字都是其他的类在这个联系中扮演的角色名字,它可以简单的是在联系另一端的类的名字(只要使用这个类名字不导致歧义)。参与属性的值是一个有关实例的标识。对于其中可以有很多有关实例的联系,这里的一个参与属性按上述描述来命名但后缀着
(s),它是从这个状态类到一个搜集类的映射,这个搜集的成员是有关的那些实例。 - 运算。类的运算规定它的实例的行为。运算是从这个类的那些实例和输入参数类型的那些实例(的叉积),到另一个(输出)参数类型的那些实例(的叉积)的映射。如若特性或参与属性是一个实例知道什么的抽象,则运算是一个实例做什么的抽象。
- 约束。其他的责任通过符合约束来承担。约束是对一个类或一个类的实例要求为真的那些事实的陈述。约束以关于属性值或约束的逻辑句子的形式来表达。一个实例符合这个约束,如果这个逻辑句子对这实例为真。一些约束固有于建模构造中,并可轻易的使用图形来表示;另一些约束特定于特殊的模型,并使用规定语言来陈述。
- 注解。注解(note)是描述一些一般性注释或关于模型某部分的特殊约束的自由文本的主体。前导于使用规定语言捕获约束,注解可以用在早期的高层视图中,注解可以通过提供解释和例子进一步的澄清一个规则。注解还可以用于不涉及规则的有“一般性利益”的注释。这些注解可以伴随于模型图形。
- 请求
- 请求(request)是从一个对象(发送者)发送到另一个对象(接收者)的一个消息,指导接收者履行它的责任。特别是,一个请求可以针对一个特性的值,针对一个参与属性的值,针对一个运算的应用,或针对一个约束的真值。
- 实现
- 责任的实现(realization)规定如何承担责任。一个实现被陈述为给出承担责任的必要和充分条件的逻辑句子。
- 模型下部结构构造
- 建模构造是以视图来体现的,并且被包装为模型,提供文档元素比如文字描述。
- 视图。视图是主题域、类、联系、责任、属性、约束和注解(和可能的其他视图)的搜集,为特定用途而组装或建立并覆盖特定范围。视图可以覆盖整个建模领域或只是这个领域的一部分。
- 层次。层次是一个视图的覆盖范围和详细程度的指定。有多个层次的视图。
- 环境。环境是概念空间,就是说在其中概念有一致的含义和用于这个概念的一个或多个一致的的名字。所有视图都为特定环境而开发。
- 术语表。术语表是在一个环境中可以用来定义概念(视图、主题域、类、联系、责任、属性和约束)的所有术语的名字和描述的搜集 。模型术语表是出现在一个模型的视图中的所有定义了概念的名字和描述的搜集。
- 模型。模型是一个或多个视图和与之一起的叙事描述和对视图及在模型的视图中使唤的视图构件(类、责任等)的规定语言的包装。
参见
[编辑]- Crow脚注法。
- Enterprise Architect,支持IDEF1X。
- IDEF0。
- EXPRESS,形式化于STEP (ISO 10303)。
- DBeaver,它的实体联系图缺省使用IDEF1X表示法[16]。
引用
[编辑]![]() 本条目引用的公有领域材料来自国家标准技术研究所的网站或文档。
本条目引用的公有领域材料来自国家标准技术研究所的网站或文档。
- ^ 1.0 1.1 1.2 1.3 1.4 1.5 FIPS Publication 184 (页面存档备份,存于互联网档案馆) released of IDEF1X by the Computer Systems Laboratory of the National Institute of Standards and Technology (NIST). 21 December 1993.
- ^ IDEF1 Information Modeling - A Reconstruction of the Original Air Force Wright Aeronautical Laboratory Technical Report AFWAL-TR-81-4023 (PDF). [2020-11-25]. (原始内容存档 (PDF)于2008-11-22).
- ^ IEEE 1998, p. iii
Bruce 1992, p. xii - ^ Systems Engineering Fundamentals. (页面存档备份,存于互联网档案馆) Defense Acquisition University Press, 2001.
- ^ IEEE Standard for Conceptual Modeling Language Syntax and Semantics for IDEF1X97(IDEFobject) (PDF).
- ^ ISO/IEC/IEEE 31320-2:2012 (页面存档备份,存于互联网档案馆) Information technology — Modeling Languages — Part 1: Syntax and Semantics for IDEF0.
ISO/IEC/IEEE 31320-2:2012 (页面存档备份,存于互联网档案馆) Information technology — Modeling Languages — Part 2: Syntax and Semantics for IDEF1X97 (IDEFobject). - ^ What is a Surrogate Key? - Definition from Techopedia. Techopedia.com. [2020-02-21]. (原始内容存档于2020-02-21) (英语).
- ^ 这种对二元关系的类型的定义可见于如下:
- Kilp, Mati; Knauer, Ulrich; Mikhalev, Alexander. Monoids, Acts and Categories: with Applications to Wreath Products and Graphs. Berlin: De Gruyter. 2000: 3. ISBN 978-3-11-015248-7.
- Peter J. Pahl; Rudolf Damrath. Mathematical Foundations of Computational Engineering: A Handbook. Springer Science & Business Media. 2001: 506. ISBN 978-3-540-67995-0.
- Eike Best. Semantics of Sequential and Parallel Programs. Prentice Hall. 1996: 19–21. ISBN 978-0-13-460643-9.
- Robert-Christoph Riemann. Modelling of Concurrent Systems: Structural and Semantical Methods in the High Level Petri Net Calculus. Herbert Utz Verlag. 1999: 21–22. ISBN 978-3-89675-629-9.
- ^ 9.0 9.1 Codd, Edgar Frank. A Relational Model of Data for Large Shared Data Banks (PDF). Communications of the ACM. June 1970, 13 (6): 377–387 [2020-04-29]. doi:10.1145/362384.362685. (原始内容存档 (PDF)于2019-08-09).
- ^ Elmasri, Ramez. Fundamentals of Database Systems. Addison-Wesley. 2011: 73–74. ISBN 978-0-13-608620-8.
- ^ itl.nist.gov (1993) Integration Definition for Information Modeling (IDEFIX) (页面存档备份,存于互联网档案馆). 21 Dec 1993.
- ^ STRAP SECTION 2 APPROACH (页面存档备份,存于互联网档案馆). Retrieved 30 September 2008.
- ^ Mary E.S. Loomis (1987). The Database Book. p. 26.
- ^ John F. Sowa (2004). [ "The Challenge of Knowledge Soup"]. published in: Research Trends in Science, Technology and Mathematics Education. Edited by J. Ramadas & S. Chunawala, Homi Bhabha Centre, Mumbai, 2006.
- ^ Gad Ariav & James Clifford (1986). New Directions for Database Systems: Revised Versions of the Papers. New York University Graduate School of Business Administration. Center for Research on Information Systems, 1986.
- ^ DBeaver Documentation - ER Diagrams. [2020-11-22]. (原始内容存档于2020-11-29).
延伸阅读
[编辑]- Thomas A. Bruce (1992). Designing Quality Databases With Idef1X Information Models. Dorset House Publishing.
- Y. Tina Lee & Shigeki Umeda (2000). "An IDEF1x Information Model for a Supply Chain Simulation"(页面存档备份,存于互联网档案馆).
外部链接
[编辑]- ISO/IEC/IEEE 31320-2:2012(页面存档备份,存于互联网档案馆)
- FIPS Publication 184 Announcing the IDEF1X Standard December 1993 by the Computer Systems Laboratory of the National Institute of Standards and Technology (NIST). (Withdrawn by NIST 08 Sep 02 see Withdrawn FIPS by Numerical Order Index)
- Federal Register vol. 73 / page 51276(页面存档备份,存于互联网档案馆) withdrawal decision
- Overview of IDEF1X(页面存档备份,存于互联网档案馆) at www.idef.com
- IDEF1X(页面存档备份,存于互联网档案馆) Overview from Essential Strategies, Inc.
| ||||||||||||||||||||||